Hydra is a lightweight vocabulary to create hypermedia-driven Web APIs.
By specifying a number of concepts commonly used in Web APIs it enables
the creation of generic API clients.
To participate in the development of this specification, please join the
Hydra W3C Community Group. If
you have questions, want to suggest a feature, or raise an issue, please send a mail to the
public-hydra@w3.org mailing list.
Introduction
Coping with the ever-increasing amount of data becomes
increasingly challenging. To alleviate the information overload put on
people, systems are progressively being connected directly to each
other. They exchange, analyze, and manipulate humongous amounts of
data without any human interaction. Most current solutions, however,
do not exploit the whole potential of the architecture of the World
Wide Web and completely ignore the possibilities offered by Linked Data
technologies.
The combination of the REST architectural style and the Linked
Data principles offer opportunities to advance the Web of machines
in a similar way that hypertext did for the human Web. Most
building blocks exist already and are in place but they are rarely
used together. Hydra tries to fill that gap. It allows data to be
enriched with machine-readable affordances which enable
interaction. This not only addresses the problem that Linked Data
is still mostly read-only, but it also paves the way for a
completely new breed of interoperable Web APIs. The fact that it
enables the creation of composable contracts means that
interaction models of Web APIs can be reused at an unprecedented
granularity.
Conformance
This specification describes the conformance criteria for
Hydra API documentations
and Hydra clients. These criteria are
relevant to authors, authoring tool implementers, and client
implementers. All authoring guidelines, diagrams, examples, and notes
in this specification are non-normative, as are all sections
explicitly marked as non-normative. Everything else in this
specification is normative.
Conformance for Hydra clients should probably not be
specified in this document.
Add normative statements
The key words MUST, MUST NOT, REQUIRED, SHALL, SHALL NOT, SHOULD,
SHOULD NOT, RECOMMENDED, NOT RECOMMENDED, MAY, and OPTIONAL in this
specification have the meaning defined in [[!RFC2119]].
Hydra at a Glance
The basic idea behind Hydra is to provide a vocabulary which enables a
server to advertise valid state transitions to a client. A client can
then use this information to construct HTTP requests which modify the
server’s state so that a certain desired goal is achieved. Since all
the information about the valid state transitions is exchanged in a
machine-processable way at runtime instead of being hardcoded into the
client at design time, clients can be decoupled from the server and
adapt to changes more easily.
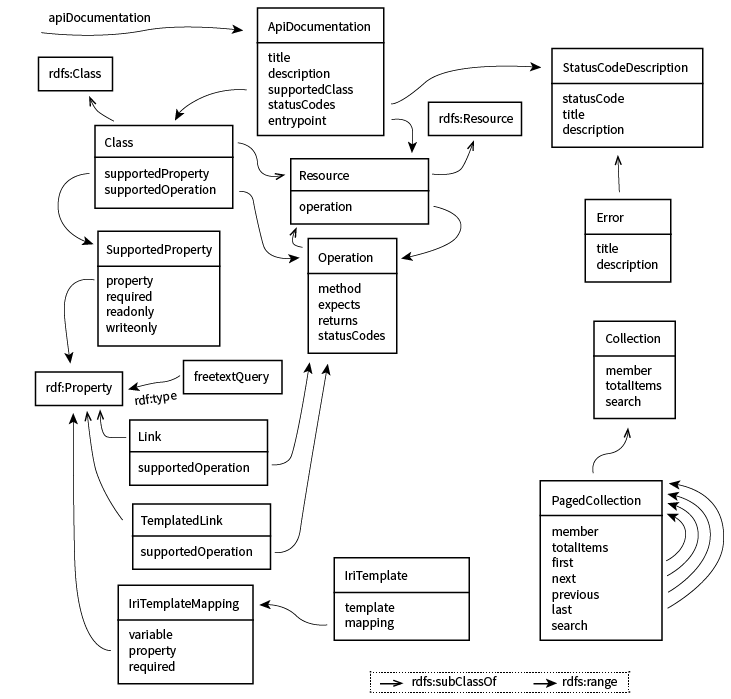
The namespace of the Hydra core vocabulary is
http://www.w3.org/ns/hydra/core#, and the suggested prefix
is hydra. The figure below illustrates the vocabulary (the
figure’s goal is to show how Hydra is used rather than its precise
definition).
Is this illustration clear enough or is it confusing?
Feedback would be much appreciated.
The Hydra core vocabulary
Add ranges for Operation "members"
An alphabetical index of the classes and properties of Hydra is
given below. All the terms are hyperlinked to their detailed
description for quick reference.
The used prefixes should be documented somewhere.
Using Hydra
Throughout this section, a simple Web API featuring an issue tracker
will be used to illustrate how Hydra can be used. The Web API enables
its users to file new issues, modify or delete existing ones, and
to comment them. For the sake of simplicity, orthogonal aspects such
as authentication or authorization are not covered.
Adding Affordances to Representations
The exemplary Web API has to expose representations of issues and
comments. To enable interaction with those resources, a client has
to know which operations the server supports. In human-facing
websites such affordances are typically exposed by links and forms
and described in natural language. Unfortunately, machines can not
interpret such information easily. The solution that presents itself
is to reduce the language to a small number of unambiguous concepts
which are easily recognizable by a machine client. Hydra formalizes
such concepts.
The simplest and most important affordance on the Web are
hyperlinks. Without them, it would be impossible to browse the Web.
Users typically select the link based on the text it is labeled
with. To give machines a similar understanding, links can be
annotated with a link relation type—a registered token or a
URI identifying the semantics of the link. The following example
shows how such a typed link is used in HTML to reference a
stylesheet.
In Linked Data, the link relation type corresponds to the property
itself. An example in JSON-LD would thus look as follows.
Generally, a client decides whether to follow a link or not based on
the link relation (or property in the case of
Linked Data) which defines its semantics. There are however also
clients such as Web crawlers which simply follow every link
intended to be dereferenced. In HTML this usually means that all
links in anchor elements (the <a> tag) are
followed but most references in link elements (the
<link> tag), such as used in the example above,
are ignored. Since in RDF serializations no such distinction exists,
the best a client can do is to blindly try to dereference all URIs.
It would thus be beneficial to describe in a machine-readable manner
if a property represents a link intended to be
dereferenced or solely an identifier. Hydra's
Link class does just that. It can be used to define properties
that represent dereferenceable links. In the exemplary Web API used
throughout this section, it can be used to define a property
linking issues to their comments:
In the example above, a property identified with the URL
http://api.example.com/vocab#comments is defined to be
of the type Link. This is enough information for a client
understanding Hydra to know that the value of the
comments property in the following example is intended
to be dereferenced.
It is recommended to dereference resources that are
within an API's domain. This may prevent possible issues with cross-site
scripting or obtaining resources which might have no meaning
to the client or such that the client would be unable to interpret.
Still, there is no formal prohibition of dereferencing resources
linked with well-known properties, e.g. rdf:seeAlso.
In the example above, the value of the comments
property is a JSON object with an @id member. This is
JSON-LD's convention to distinguish between strings and IRIs. By
using JSON-LD's type-coercion feature, the representation can be
made even more idiomatic:
While links are enough to build read-only Web APIs, more powerful
affordances are required to build read-write Web APIs. Thus, Hydra
introduces the notion of operations. Simply speaking, an
Operation represents the information necessary for a client
to construct valid HTTP requests in order to manipulate the server's
resource state. As such, the only required property of an
Operation is its HTTP method. Optionally, it is
also possible to describe what information the server expects
or returns, including additional information about HTTP
status codes that might be returned. This helps a developer to
understand what to expect when invoking an operation. This
information has, however, not to be considered as being complete;
it is merely a hint. Developers should, e.g., expect that other
HTTP status codes might be returned and program their clients
accordingly.
The following example illustrates how representations can be
augmented with information that enables clients to interact with
them.
The example above references Hydra's context to map properties such
as operation and method and values like
Operation to URLs that unambiguously
identify these concepts. It would be similarly valid JSON-LD if
these mappings would be directly embedded into the representation
or if the full URLs would be used instead. Typically, however, the
context is the same for a lot of representations in a Web API and
it thus makes sense to reduce the response size by leveraging a
remote context that can easily be cached by a client.
It is worth mentioning that due to the fact that Hydra is built on
RDF, which is a graph, it may happen that a related resource
(an object of the relation) may not be fully described in the
resource's payload. In several circumstances (i.e. payload terms
defined in API documentation sa described in
Documenting a Web API
or IriTemplate expected as a related resource as described in
Templated Links) client may
discover no additional statements describing it. These rules should
be considered by the client in following scenarios:
in case of an object expected to be a hypermedia resource does not have all
the necessary statements for which it is a subject, the client SHOULD look in the
API documentation for more details
in case the mentioned object, after consulting an API documentation, still
does not have all the necessary statements for which it is a subject and both
mentioned object's Url and Url of the initially obtained resource has the
same scheme and authority (by means of [[!RFC3986]] sections 3.1 and 3.2), the client
SHOULD de-reference that Url. If the resource does not have the same scheme and
authority the client MAY choose to de-reference it (for example if the resource
originates from another API well-known to the client)
in case the mentioned object still does not have all the necessary
statements for which it is a subject (i.e. de-referencing it failed
or statements are missing), the client SHOULD either ignore the whole
statement (i.e. for display purposes) or throw an exception (i.e. an
IriTemplate is about to be resolved and de-referenced)
Example of each of the situations are as follows:
where
resource http://api.example.com/people should have an IriTemplate available
as there is a complete definition of the template available at http://api.example.com/doc/.
resource http://api.example.com/events should not have an Iri template exposed as there
are no additional details available, neither in the initial resources' payload nor in the API documentation.
Keep in mind that any resource described by any hypermedia control
may fail at runtime due to various reasons. Operation details
such as returns or possibleStatus may also vary at runtime,
which means client SHOULD always verify received payloads at runtime.
Documenting a Web API
In Web APIs, most representations are typically very similar.
Furthermore, resources often support the same operations. It thus
makes sense, to collect this information in a central documentation.
Traditionally, this has been done in natural language which forces
developers to hardcode that knowledge into their clients. Hydra
addresses this issue by making the documentation completely
machine-processable. The fact that all definitions can be identified
by URLs enables reuse at unprecedented granularity.
Hydra's ApiDocumentation class builds the foundation for
the description of a Web API. As shown in the following example,
Hydra describes a API by giving it a title, a short description, and
documenting its main entry point. Furthermore, the classes known to
be supported by the Web API and additional information about status
codes that might be returned can be documented. This information
may be used to automatically generate documentations in natural
language.
In Linked Data, properties are, just as everything else, identified
by IRIs and thus have global scope which implies that they have
independent semantics. In contrast, properties in data models as
used in common programming languages are class-dependent. Their
semantics depend on the class they belong to. In data models classes
are typically described by the properties they expose whereas in
Linked Data properties define to which classes they belong. If no
class is specified, it is assumed that a property may apply to every
class.
These differences have interesting consequences. For example, the
commonly asked question of which properties can be applied to an
instance of a specific class can typically not be answered for
Linked Data. Strictly speaking, any property which is not explicitly
forbidden could be applied. This stems from the fact that Linked Data
works under an open-world assumption whereas data models used by
programmers typically work under a closed-world assumption. The
difference is that when a closed world is assumed, everything that
is not known to be true is false or vice-versa. With an open-world
assumption the failure to derive a fact does not automatically imply
the opposite; it embraces the fact that the knowledge is
incomplete.
Mention that Hydra classes are dereferenceable
resources.
Since Hydra uses classes to describe the information expected or
returned by an operation, it also defines a concept to describe the
properties known to be supported by a class. The following example
illustrates this feature. Instead of referencing properties directly,
supportedProperty references an intermediate data structure,
namely instances of the SupportedProperty class. This makes
it possible to define whether a specific property is required or
whether it is read-only or write-only depending on the class it is
associated with.
All instances of a specific class typically support the same
operations. Hydra therefore features a supportedOperation
property which defines the operations supported by all instances of
a class.
The same feature can be used to describe the operations supported
by values of a Link property. This is often helpful when
certain operations depend on the permissions of the current user. It
makes it, e.g., possible to show a "delete" link only if the current
user has the permission to delete the resource. Otherwise, the link
would simply be hidden in the representation.
Example shown below describes the operation's expected and returned
value as a dereferencable resource (an RDF resource of a given class),
but the vocabulary is not limited to only those originating
from RDF and is enabled to other types of resources.
Please note that in case of multiple either returned or expected types
provided, client SHOULD assume the set includes any of the types,
but not limited to those types and client SHOULD interpret received
payload at runtime for possible discrepancies.
In addition to expected/returned resources, it is also possible to
express similar features for headers with returnsHeader and
expectsHeader predicates which provides a simple set of header
names. Client SHOULD apply respective header semantics when creating
or receiving a request natural for the protocol in use.
The example above enable an HTTP client to prepare a proper cross-site
pre-flight request so the server exposes enlisted headers for the client.
The client is also aware of the user authentication requirement necessary
for the operation invocation.
For more complex scenarios it is also possible to expand selected header
specification with both name and possible values, i.e. when defining
expected Content-Type values of resources that can be uploaded.
In case multiple possible values are provided, client SHOULD assume
that the set includes any of the values, but not limited to those values.
In order to change that default behavior it is possible to use closedSet
predicate on the header specification indicating that the set of provided
values is, well, closed and no other values are available. In both case the client
SHOULD interpret received payload at runtime for possible discrepancies.
To wrap up everything altogether, it is also possible to attach atomic
operations supported by, well, supported property itself. This might
come in handy for scenarios, when resource can be partially modified.
It can be achieved with two approaches, both having advantages and
disadvantages.
First approach would involve adding a supportedOperation to the
intermediate structure of SupportedProperty.
This way prevents from leaking API specific features from the API itself
to i.e. externally defined properties. Data aggregators won't assume that
each instance with a given property could have such an operation.
Another approach would require the API to elevate a specific property
to Link, which can accept a supportedOperation. This
is more intuitive in APIs operating with internally used vocabularies
where assumption that every instance with that very specific property
has the operation attached available.
Direct usage of supportedOperation on rdf:Property
without elevating it to the Link SHOULD NOT be implemented as clients
may not discover such a construct correctly.
These are the simple example scenarios and possible usages are not
limited to those described above.
Due to the fact an ApiDocumentation as all other resources may fail
at runtime, it is important to take countermeasures.
A simple strategy to try to recover from such a situation would be to reload
the ApiDocumentation and redo all pre-computations that were
based on the ApiDocumentation (or at least those that lead
to the current failure). Another, simpler approach would require
an application to show an error message with option to return
to a previous or home screen.
Describe the various properties of an operation.
Hydra also allows enriching both ApiDocumentation and
hypermedia controls with human-readable descriptions by applying
title and description (as shown in the examples above).
The former states a name of such a decorated element that could
be displayed as a label. The latter provides its description
to be presented i.e. as a hint.
Aforementioned title and description SHOULD take precedence
over standard rdfs:label and rdfs:comment.
There is one more feature related to how Linked Data works. Consider the
example below written in turtle syntax:
and how it could be transformed with JSON-LD framing process:
As you can see, additional details about ex:SomeType went
missing, while this shouldn't happen. The fact that the IRI mentioned
is an rdfs:Class may be meaningful for a correct interpretation
of the received payload and this is a sole reason of why a Client
SHOULD NOT disregard other parts of the payload that are not directly
related to the API documentation or other hypermedia controls.
Discovering a Hydra-powered Web API
The first step when trying to access a Web API is to find an entry
point. Typically, this is done by looking for documentation on the
API publisher's homepage. Hydra enables the API's main entry point
to be discovered automatically if the API publisher marks his
responses with a special HTTP Link Header as defined in [[RFC5988]].
A Hydra client would look for a Link Header with a relation type
http://www.w3.org/ns/hydra/core#apiDocumentation (this is
the IRI identifying the hydra:apiDocumentation property).
In the following example, a Hydra client simply accesses the
homepage of an API publisher (http://www.example.com)
to find the entry point of its API. A client may use an HTTP GET or
HEAD request. The difference between the two is that the former may
return a message-body in the response whereas the latter will not;
otherwise they are identical.
The response in the example above contains an HTTP Link Header
pointing to http://api.example.com/doc/.
Retrieving that resource, the client would obtain a
Hydra API documentation defining the API's main entry
point:
Please note that in most cases the entry point will already be
known to the client. Thus, the discovery of the API documentation
using HTTP Link Headers is typically not necessary as the concepts
used in responses from the API will dereference to their
documentation.
In another scenario the ApiDocumentation would be discovered from
a bookmarked resource's representation. Api implementation SHOULD emit
the HTTP Link header on every Api response, making
the ApiDocumentation (and entry points it defines) discoverable
all the time.
Api versions
It is common to provide a separate API address after a breaking changes
update. This prevents current clients not to get broken as these may not
support these changes.
With hypermedia provided in each response payload, it may be unnecessary
to provide such an alternative API. This is due to fact the client follows
what the server provides and with proper margin for errors implemented
within that client, even breaking changes can be published on the fly.
Still, Hydra does neither have any special support for API versions, nor
prevents them. It's fully an implementers decision on if and how
to provide the API features.
Advanced Concepts
Describe Hydra's Resource class? Or should that better be
described somewhere in the beginning?
Collections
In many situations, it makes sense to expose resources that reference
a set of somehow related resources. Results of a search query or
entries of an address book are just two examples. To simplify such
use cases, Hydra defines the two classes hydra:Collection and
hydra:PartialCollectionView.
A hydra:Collection can be used to reference a set of resources
as follows:
As shown in the example above, member items can either consist of
solely a link or also include some properties. In some cases embedding
member properties directly in the collection is beneficial as it may
reduce the number of HTTP requests necessary to get enough information
to process the result.
Since collections may become very large, Web APIs often chose to
split a collection into multiple pages. In Hydra, that can be achieved
with a hydra:PartialCollectionView. It describes a specific
view on the collection which represents only a subset of the collection's
members. A PartialCollectionView may contain links to the
first, next, previous, and lastPartialCollectionView which allows a client to find all members
of a Collection.
Say that all these properties are optional? What about
first and, perhaps more interestingly, last?
Member assertions
A memberAssertion is a way to declare additional, implicit statements about
members of a collection. Statements which may otherwise
be missing from the respective member resources inlined in a collection's
representation.
In the above example, adding a memberAssertion node to the collection instructs the
client that every member of this collection is linked to the subject
by the property. It could be written as a SPARQL triple pattern below, where
?m would be substituted by each member of the collection.
A memberAssertion MUST use two and only two of the subject, property
and object predicates. There memberAssertion predicate MAY have more than one
such blocks, each expressing different relations between the collection members and other resources.
It's important to point out that the subject, property
and object predicates are defined within the Hydra namespace and are not
rdf terms.
Templated Links
Sometimes, it is impossible for a server to construct a URL because
the URL depends on information only known by the client. A typical
use case are URLs which enable a client to query the server. In such
a case, the server cannot construct the URL because it does not know
the query the client is interested in. What the server can do however,
is to give the client a template to construct such a URL at runtime.
In Hydra, the IriTemplate class is used to do so.
An IriTemplate consists of a template literal and a set
of mappings. Each IriTemplateMapping maps a
variable used in the template to a property and may
optionally specify whether that variable is required or not.
The syntax of the template literal is specified by its datatype and
defaults to the [[!RFC6570]] URI Template syntax, which can be
explicitly indicated by hydra:Rfc6570Template.
The example above maps the variable q to Hydra's
freetextQuery property and marks it as required.
As its name suggests, the freetextQuery property can be used
for free text queries.
A template syntax only details how to fill out simple string values,
but not how to derive such string values from typed values,
language-tagged strings, or IRIs. Hydra addresses this by
specifying how such values are to be serialized as strings. The
serialization of an IriTemplate's variables can be described
by setting the variableRepresentation property to
BasicRepresentation or ExplicitRepresentation. The
BasicRepresentation represents values by their lexical form. It
omits type and language information and does not differentiate between
IRIs and literals. The ExplicitRepresentation, on the other
hand, includes type and language information and differentiates
between IRIs and literals by serializing values as follows:
IRIs are represented as-is.
Literals, i.e., (typed) values and language-tagged strings are
represented by their lexical form, surrounded by a single pair of
doubles quotes (").
If a literal has a language, a single @ symbol is
appended after the double-quoted lexical form, followed by a
non-empty [[BCP47]] language code.
If a literal has a type, two caret symbols
(^^) are appended after the double-quoted literal,
followed by the full datatype IRI.
In both representations characters MUST NOT be escaped. In case the
representation format is not explicitly described, clients SHOULD
use the BasicRepresentation by default.
Although ExplicitRepresentation use of
@ and ^^ is similar, it is not the
same as the [[Turtle]] representation for literals. Turtle literals
require escaping of special characters, surround datatype IRIs with
angular brackets (< and >), and also
allow single quotes (') to indicate literals.
ExplicitRepresentation values must not be escaped, IRIs must
not be surrounded by any character, and only double quotes can
indicate literals.
Below are some example values serialized in the different
representations as well as the result of expanding the IRI template
http://example.com/find/{value} with the respective
value.
Similar to how Hydra's Link class allows the definition of
properties that represent hyperlinks as described in
,
the TemplatedLink class allows the definition of properties
whose value are IRI templates. Hydra predefines one such property,
namely the search property which can be used to document
available search interfaces.
IRI expansion should be performed with respect to the specification
behind the IRI template type (RFC 6570 by default), and the product
of this process SHOULD be an IRI. When the produced IRI is relative,
the client SHOULD stick to RFC 3986 sections 5.1.3 and 5.1.4 to be compatible
with most RDF serializations that support relative IRIs. Still, it may be
preferred to use another base URI for the expansion process, which
makes the resolveRelativeTo term useful. It allows to switch the
IRI template expansion algorithm so the base URI is established using
current link context, which is a subject of the relation pointing to an
IriTemplate instance. In case that subject is a relative URI,
default behavior SHOULD be used as fallback.
The example below allows to make the product of an IRI template
expansion relative to the http://api.example.com/an-issue/ resource
by using it as its base URI, which further enables the some:operation to
be moved to i.e. API documentation level rather to inline it.
When constructed, the IRI would effectively become similar to http://api.example.com/an-issue/1234,
with the relative part {id} appended to the link context URL.
IRI template operations
There are circumstances in which client would like to perform an operation
not knowing the final IRI of the resource to be called. This case is especially
in force when working with collections - client may want to add a new
collection member, or it may need to provide more details while searching
with other protocol's method (i.e. POST instead of GET in case of an HTTP).
This is achievable by attaching a supportedOperation to the property
that connects a subject of that relation with its IRI template
as described in the previous part of this document. Please note that
client is still allowed to use the defined link and custom operation's
method is optional.
The example above allows client to either invoke an HTTP GET or POST
call on http://api.example.com/issues?search=search_string resource.
The example above allows client to invoke only an HTTP POST
call on http://api.example.com/issues?find=search_string resource as
the described relation of find is not a Link.
Supported property data source
There are circumstances in which an API would like to inform a client on
when to obtain values to feed data structures with details. Having all the
necessary components like supported property, collection and IRI templates,
it is possible to drive the client and direct it with links and operations
to the data sources.
It is doable by attaching either a collection or search
predicate to instance of supportedProperty or to property.
In such case client SHOULD use assume that the relation leads to
the collection of values compatible with the supported property's range
and can be used to feed data structures with the supported property.
It is recommended (but not mandatory) to use freetextQuery
variable mapping in case of the search predicate as it has a
well defined semantics and takes the burden of interpretation from
the client.
While it is possible to provide such links in both API documentation
and within the received payload, client SHOULD use the latter link first
if applicable. This is due to fact the the server may want to put additional
context to narrow the collection of viable values. Redefinition does not
make the more general one obsolete though and and can be used as a fallback.
The example above instructs a client that every resource of type
schema:Event can have a relation of schema:actor, the objects of which the
client can obtain using the search link provided.
Description of HTTP Status Codes and Errors
HTTP status codes have well defined semantics and can be used to
signal the outcome of an operation. Unfortunately, however, HTTP
status codes by themselves are often not specific enough, making it
difficult to understand the real cause of an error. For
instance, a 429 Too Many Requests response is rarely
informative enough by itself. To address this issue, Hydra defines
a Status class which allows additional
information to be associated with an HTTP status code.
An ApiDocumentation or an Operation may document the
status codes that might be returned by the server using the
possibleStatus property as described in
. This allows
a developer to understand what to expect when invoking an operation.
It has, however, not to be considered as an extensive list of all
potentially returned status codes; it is merely a hint. Developers
should expect to encounter other HTTP status codes as well.
A server may also return a Status directly in
a response. When doing so, it often makes sense to subclass the
Status to make its semantics more explicit.
Hydra defines just one such subclass, namely the Error class.
This provides an extensible framework to communicate error details to
a client.
Furthermore, a Status or Error returned by the server can also
be given an identifier. When dereferenced, the Error resource can provide
more detailed information or possible ways to resolve the problem, if applicable.
Finally, the server SHOULD provide error descriptions using an [[!RFC7807]] standard
by using an application/problem+json response. When doing so, the server also MUST provide
an additional header pointing to either the built-in Hydra http://www.w3.org/ns/hydra/error
context or any JSON-LD context that maps the terms type, title, detail,
status and instance the same way as the standard one.
While the built-in context makes the response fully compatible with the mentioned specification,
properties not defined in the standard Hydra's error context won't be visible for Hydra aware processors.
To overcome this, it is possible to declare a custom context pointed the same way, that would combine standard
Hydra's standard error context and an additional JSON-LD context with either the @vocab
or custom property mappings telling the processor on how to interpret those custom error properties.
Resources provided may have an additional hint pointing to an Error type like in the example
above, but it is not mandatory to do so as all resources described with application/problem+json
are considered hydra:Error.
It is worth to mention that it may happen (i.e. due to proxy behavior) the value of the status property
will differ to the one received from the protocol layer.
Client initiated pagination
There are situations when a client would like to provide a specific
collection limitations, i.e. by providing query-language like member
offset and limit or some specific page index and number of members
per page. This is doable with offset/limit or
pageIndex/limit predicates.
With those, it is possible to bind a template variables mapped
with externally obtained values (i.e. user interaction) the same way
as with other mappings.
While the predicates enlisted above accepts non-negative integer
numbers, there is also a possibility of providing a custom page
reference expressed via pageReference predicate. It is possible
to provide a custom page identifier (i.e. a GUID or a letter)
instead of a number.
Extensions
While Hydra Core Vocabulary allows addressing many usage scenarios,
not every aspect of API behavior can be covered. This
applies especially to querying, resource projection or data structure
description. This is due to fact that Hydra is meant to be as light
as possible forcing to drop some of the features out of its scope.
That is why there is a possibility of hinting a client on what kind
of extensions may be found or used in the received payloads.
After discovering an extension predicate in the API documentation,
client can assume additional details are available described with
complementary vocabularies.
It is up to the used vocabulary to define how these additional details should be
interpreted. In case client does not recognize these extensions,
additional details should be ignored and base Hydra interpretation
should be in force.
Server SHOULD NOT use extensions to add statements that are in
contradiction to base Hydra interpretation so the client is not confused.
Server SHOULD also keep multiple extensions describing adequate
knowledge in line regarding their description (i.e. data structure
descriptions in various vocabularies should not cause differences).
Client can express its preferences through the Prefer HTTP header
by pointing the preferred extensions via IRIs as on the example below.
The client SHOULD use the Prefer HTTP header [[!RFC7240]] with
the hydra.extension preference as an iri attribute having
the IRI of the extension as value to hint the server about the extension
it supports. Multiple preferences can be expressed by providing multiple
Prefer header values.
Server MUST implement Prefer header handling according to
the [[!RFC7240]] and implementers should proceed with caution.
Classes
Properties
Acknowledgements
The authors would like to thank the following individuals for contributing
their ideas and providing feedback for writing this specification:
Arnau Siches, elf Pavlik, Karol Szczepański, Mark Baker, Martijn Faassen,
Matthias Lehmann, Ruben Verborgh, Ryan J. McDonough, Sam Goto,
Thomas Hoppe, Tomasz Pluskiewicz, @wasabiwimp (on GitHub).